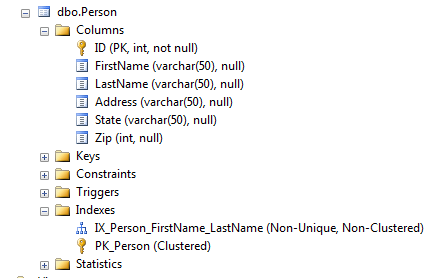
Shrinking the SSISDB
The SQL Server Integration Services (short SSIS) are a great tool to move data around. Not only are they fast, they have many useful parts to make data migration a simple task. The same is true for their production use. Cleaning up their own database is a feature that most applications completely ignore. All is set-up in a way that SSIS can run for a long time without user intervention.
I was therefore surprised when our backup disk run out of space. The SSIS database grow in a matter of days from ~7 GB to 70 GB. A quick look around showed that it stored 60 Million events, what was unexpected and problematic. A bit of googling resulted in an idea to reduce the retention time. There are many examples on how to do that. Unfortunately, the one I liked the most had all scripts in screenshots, what makes copy and paste impossible. This post fixes that, explains the reason to do the different steps and points out possible pitfalls and their prevention.
Before you Start
Don’t try anything without a backup. If something goes wrong, the backup may be the only thing that stands between you and hours of work to get SSIS back to work.
Next, limit the auto-growth of your SSIS database and the log files. The shrinking will create a lot of log entries and if you try to reduce it too much at once you fill up your disk again and the job throws an exception. Set the maximum size for the log files near the maximum you can put on the disk. You shrink it later, but until then every gigabyte helps.
Next, limit the auto-growth of your SSIS database and the log files. The shrinking will create a lot of log entries and if you try to reduce it too much at once you fill up your disk again and the job throws an exception. Set the maximum size for the log files near the maximum you can put on the disk. You shrink it later, but until then every gigabyte helps.
The last step for preparation is to disable all the tasks who use SSIS. It’s simpler to shrink the database when you aren’t constantly blocked by a running SSIS job. You can deactivate the jobs in the overview of the jobs section in the SQL Server Agent:

Uncheck all the SSIS jobs and click OK. To turn them back on later, you simply check them and again and click on OK to save those changes.
Start Shrinking
Right after you have your backup and limited the auto-growth of the database files you should change the recovery mode of the SSISDB to SIMPLE. There are no *.log backups and you are unable to recover your database to a specific point in time. On the plus side, you don’t need the space for the archived transaction log backups.
Keep a note about the current recovery mode so that you can go back to the right one when you are done.
USE [master]
GO
SELECT name, recovery_model_desc
FROM sys.databases
WHERE name = 'SSISDB'
GO
ALTER DATABASE [SSISDB] SET RECOVERY SIMPLE WITH NO_WAIT
GO
Now check what values are set for the catalog properties:
USE SSISDB
GO
SELECT * FROM [catalog].catalog_properties
USE [master]
GO
SELECT name, recovery_model_desc
FROM sys.databases
WHERE name = 'SSISDB'
GO
ALTER DATABASE [SSISDB] SET RECOVERY SIMPLE WITH NO_WAIT
GO
Now check what values are set for the catalog properties:
USE SSISDB
GO
SELECT * FROM [catalog].catalog_properties

The two Boolean fields must be set to true. If they are false the clean-up script will not do any work.
The next step is to reduce the retention time that is controlled by the variable
UPDATE SSISDB.[catalog].[catalog_properties]
SET property_value=200
WHERE property_name='Retention_window'
With the retention time reduced, it is now time to start the clean-up job:
EXEC [internal].[cleanup_server_retention_window]
Retention_window. This values specify how many days the data is kept around. The default value is to keep data for a year (365 days). If you want to reduce it to 7 days, then you may be tempted to do it in one step. It can work, but most likely it will run for hours and then fail. To reduce risk of spending hours without any progress, try smaller steps. Reduce it in the first attempt to 200 days. If it works, keep reducing it by 50 days. If it isn’t working, you can reduce the retention time by 1-5 days per step.UPDATE SSISDB.[catalog].[catalog_properties]
SET property_value=200
WHERE property_name='Retention_window'
With the retention time reduced, it is now time to start the clean-up job:
EXEC [internal].[cleanup_server_retention_window]
If the clean-up was successful, you repeat it with a lower retention time until you reach a database size you can work with.
How big is your Database?
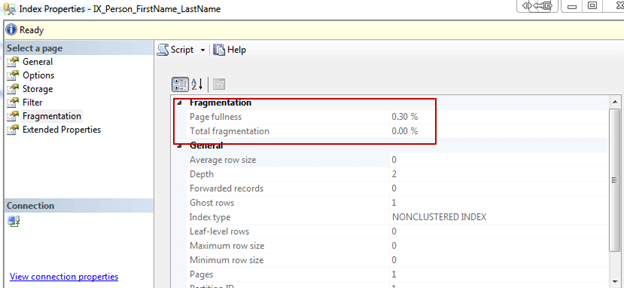
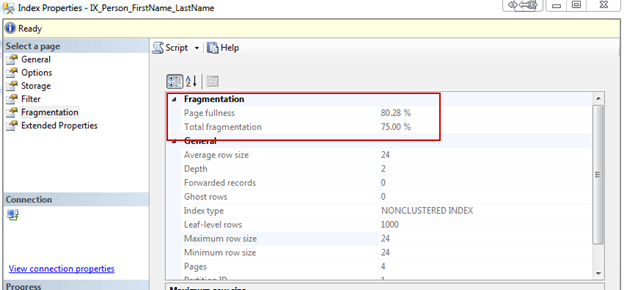
Looking at the size of the different database files will get you only half the picture. That is just the size it takes on the disk. The database keeps free space allocated to improve the overall performance. When you delete a great number of records then that no longer needed space isn’t returned to the operating system. SQL Server has built-in reports to see how much of the file size is really used. You can find those reports in the Management Studio of SQL Server on the context menu of your database:

The report looks something like the next picture, where the free space is marked in green:

Shrinking the Database
Now we can finally come to the part where we can give disk space back to the operating system. SQL Server Management Studio offers a simple way to do that.

Go Back to the Initial Recovery Mode
With a successful reduction of the size you now can go back to the recovery mode you had before we start.
ALTER DATABASE [SSISDB] SET RECOVERY FULL WITH NO_WAIT
GO
Next make a backup of the now shrinked database. If something else goes wrong, you don’t need to redo the whole work of reducing the retention time.
ALTER DATABASE [SSISDB] SET RECOVERY FULL WITH NO_WAIT
GO
Next make a backup of the now shrinked database. If something else goes wrong, you don’t need to redo the whole work of reducing the retention time.
Don’t forget to turn your SSIS jobs on.